Software 3.0: The anti-hype way to think about building software with LLMs according to Andrej Karpathy
TLDR
-
Software is Evolving: From Deterministic Rules to Probabilistic Simulations. Traditional Software 1.0 relies on predefined, deterministic instructions. Software 2.0 (deep learning) introduced non-deterministic, black-box statistical models. Software 3.0 (LLMs) represents a new paradigm where LLMs act as “stochastic simulations of people,” specializing in natural language and demanding a re-evaluation of how we build software due to their inherent non-determinism and “jagged intelligence.”
-
Redefining Expectations: LLMs as “Stochastic Simulations of People.” To avoid frustration, developers must understand LLMs are probabilistic, non-deterministic systems that simulate human language and reasoning but don’t truly “understand” or reason like humans. This model, championed by Andrej Karpathy, emphasizes their “jagged intelligence” – incredible performance in some areas (NLP, recall) but fundamental limitations in others (e.g., precise counting, complex multi-step reasoning).
-
Building for Software 3.0: A New Design Paradigm for “Partially Autonomous Apps.” Developing with LLMs requires shifting from fully autonomous systems to “partially autonomous apps” where a “human-AI cooperation loop” is central. This paradigm prioritizes speeding up the “generation-verification loop” (e.g., with better UI/UX like diffs), keeping AI outputs manageable for human oversight, and designing systems (like APIs and HTML attributes) to be inherently more “LLM-accessible.”
Intro
The internet is awash with ‘AGI is coming!’ hype, but if you’ve actually tried building software with LLMs, you know the reality is far more nuanced.
As a person who’s been building software applications with LLMs (large language models, what most people refer to when they talk about AI these days, ie the likes of chatGPT, claude, gemini …) for the past year, I have often been frustrated by my inability to produce a good mental model when talking about building software with them to other people on the team, ie what is reasonable and unreasonable for them to do.
Due to the properties of LLMs capable of having perfectly fluid conversations with humans and the AGI hype, it’s hard to avoid the trap of anthropomorphizing these systems, and talk about them as “college-graduate interns which we guide with prompts”. But building with this mental model is going to lead to a path of constant frustration, leaving us constantly wondering why “it did not do what we asked”, and making desperate attempts to coax the model to do what we want it to do with “prompt engineering”.
I accidentally came across the talk by Andrej Karpathy, former director of AI at Tesla. And Wow! Andrej has captured and articulated how I’ve been feeling for the past year so succinctly. His mental model is what I hope everyone adapts moving forward, so that we have more well-aligned expectations and build better software. So this is going to be a personal summarization of the talk, sprinkled with some personal opinions.
From software 1.0 to software 3.0
Software 1.0, in essence, is a series of defined and deterministic instructions written for the computer to carry out certain tasks based on some input. It has been how most software has worked up until now.
Software 2.0 came after the paradigm shift when deep learning was introduced. For simplicity, lets think of deep learning systems as statistical models on steroids that are still largely black boxes: they are trained on a bunch of data to pattern-match input to output. For example, an image classifier is trained to take an image as input, and output the name of object (cat, dog, car…).
The success of deep learning essentially introduced non-deterministic behavior to software. To this day, these models are still sort of a black box, and techniques to interpret why these models do the things they do are still a work-in-progress. A software written in the paradigm of software 1.0 is capable of being traced perfectly from start to finish, and in theory we can have a 100% guarantee on its properties, but the same cannot be said of software written in the paradigm of software 2.0. If software 1.0 behaves unexpectedly, we are capable of tracing down exactly why that happened; if software 2.0 behaves unexpectedly, we can have hypotheses of why it happened, but never to the same degree of accuracy as in the case of software 1.0.
Many problems are hard to solve with pure rule-based systems, for example computer vision is a field where deep learning has been very successful. However, while deep learning does greatly enhance the capabilities of what we are capable of doing with software, we should still keep their limitations in mind. For tasks where we only care about the input and output, and don’t really care about how the result was derived, then deep learning can be a good fit; however, if the task warrants a clear explanation of every in between process, then trying to fit our task into deep learning would not be of great help.
What makes LLMs special?
Software 3.0 is the latest paradigm of LLMs. Technically, they use the same deep learning technology as software 2.0, but to model natural language (and with enormous amounts more compute). The main training task of LLMs is to do next word prediction, ie given an incomplete sentence as input, output the most probable next word. For example, given “The capital of France is”, the model has to output “Paris”.
There are many debates on whether LLMs can lead to AGI, ie human level intelligence. I personally side with the people that say it can’t. But despite not being AGI, I still believe LLMs to be quite a paradigm shift.
What I believe makes LLMs special is the usefulness of human language/text as a universal substrate for modelling most tasks we do today, especially in the age of knowledge work. Take coding for example, in a reductive sense we can think of coding as taking requirements in natural language as input, then outputting the relevant code implementations. It seems to me that a lot of non-physical tasks we do can in some sense be formulated as a natural language input/output task.
A mental model for what LLMs are, and how to think about what they can or can’t do
Ever feel like building with LLMs is like wrestling a ghost? One minute they’re brilliant, the next they’re baffling…
A great model that Andrej provided with us is to think of LLMs as ‘stochastic simulations of people’. ‘Stochastic’ should remind us that these systems are based on probability, therefore we shouldn’t expect deterministic behavior out of them; and ‘simulation’ should remind us that they don’t actually reason like humans do, even when they often seem so. They display what he calls ‘jagged intelligence’, where they are incredible in certain domains, but seem to fail at really basic tasks, for example counting the number of ‘R’s in the word refrigerator. An article by Anthropic might offer us tentative explanations of why this might be the case: they showed that LLMs can do arithmetic (for example, adding two numbers), but probably not by the way you think. Instead, they arrive at the answer using multiple linguistic circuits.
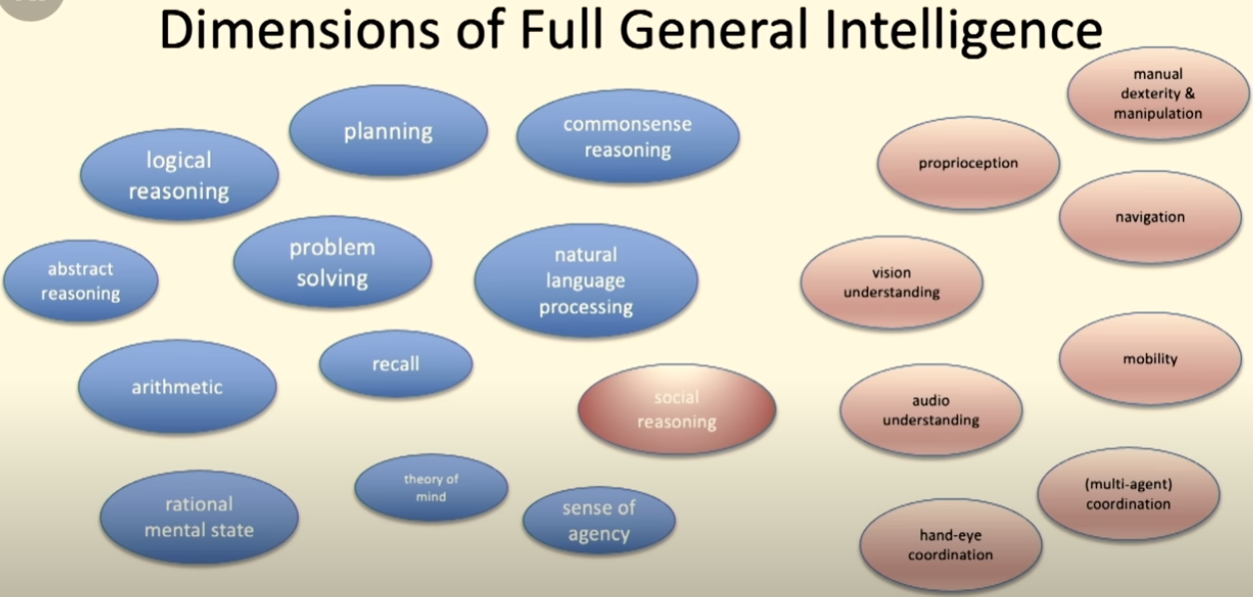
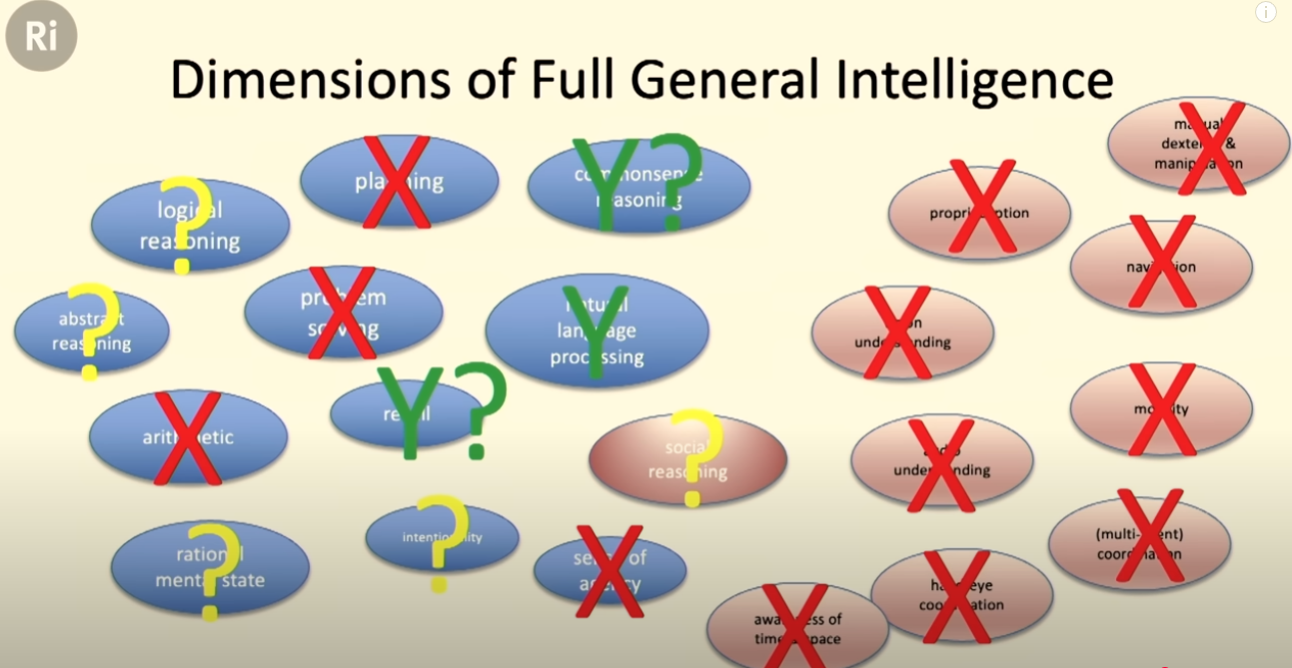
We can also try to break intelligence into multiple subdomains and think about what LLMs currently excel at. In this lecture by Professor Mike Wooldridge, he breaks down the components of ‘general intelligence’, and tentatively lists out areas where LLMs might have reached or exceeded human level, which are: natural language processing, recall and commonsense reasoning.
Building software with LLMs
Given the uniqueness of LLMs (their non-deterministic nature and their ‘jagged intelligence’), a new paradigm of designing software with them has to be adopted. He calls these new apps ‘partially autonomous apps’. Based on the task at hand, you can imagine having an ‘autonomy slider’ that you can slide up or down to determine how much agency you want to give the AI copilot.
Take coding for example. In the case of giving all the agency to the LLM, you could describe your requirements and let the LLM build it for you entirely, without manually reviewing the code, which is what people now describe as ‘vibe-coding’. While powerful, this approach is definitely limited in how complex your application can be; beyond a certain level of complexity, you might run into bugs the LLM can’t solve or features it just can’t build, essentially due to the nature of these LLMs not actually ‘understanding’ what you are trying to build. Therefore, the more useful approach would be to form a ‘human-AI cooperation loop’, where we still manually evaluate the output of these LLMs, correcting its mistakes and even doing the work ourselves if needed.
We can adjust the ‘autonomy slider’ depending on the task at hand. The more important the task/ the higher the risk of failure, the more human supervision would be needed.
Our design goals should be to try to make the generation-verification loop as fast and smooth as possible, with cleverly designed UIUX. Take coding for example, having diffs allow people engineers to verify the changes faster. We should also try to keep AI on a leash so that their outputs are too much for us to verify.
We also need to make our software more ‘accessible’ to LLMs. Take websites for example, while multimodal LLMs (ie LLMs which can take images, video, sound as input…) are capable of ‘seeing’ the website and you might have seen demos of browser automation agents clicking stuff to complete a task, it’s probably still much more error-prone and inefficient than have LLMs interact with a text-based interface (tool use).
How things might go moving forward
- LLM-first APIs/semantic APIs: we have semantic HTML that make it easier for crawlers. Maybe in the future when we decide APIs, we consider how easy it would be to directly turn it into an MCP tool. I have also considered whether building LLM-first API frameworks, for example building an MCP layer on top of
orpc, could be something useful. - HTML attributes for LLMs to interact with: we already have HTML attributes for end-to-end testing, maybe we design them to make them speak to LLMs as well.
Summary
That’s it! Like Andrej, I believe LLMs are indeed a huge paradigm shift for software moving forwards. But also, there are going to be a lot of nuance to keep in mind, a lot of new questions to be answered, and a lot of new design problems to tackle along the way.